Kubernetes是一个Docker集群管理工具,主要包含资源管理,部署运行,服务发现,扩容缩容等功能,帮助用户把所有的应用都部署在Docker Container里边,Kubernetes可以看成是一个mini的PaaS平台,主要用来帮助用户管理Docker Container。
Apache Mesos是一款开源集群管理软件,由加州大学伯克利分校的AMPLab首先开发;支持Hadoop、ElasticSearch、Spark、Storm 和Kafka等架构。Mesos 为上层的应用框架提供了资源共享,资源监控,动态扩容等集群管理功能。由于其稳定、通用等特性,越来越受到大型公司的青睐,例如Twitter、Facebook、Apple等都在生产环境中使用Mesos进行集群管理。
集成优势
Kubernetes worker节点自动扩展
一个普通的Kubernetes集群会包含若干台Master和Worker节点,这些都需要用户手动或者通过脚本去安装,如果想实现Kubernets Auto Scaling的话,需要将Kubernetes部署在一个IaaS的云平台之上,通过云平台对Kubernetes提供资源,同时对Kubernets监控,根据负载进行自动扩展,但是Kubernetes和云平台的集成稍显厚重。
Kubernetes和Mesos集成完成之后,也可以实现Worker节点的自动扩展,所有Worker节点都是自动创建的,不需要用户手动干预。详细信息在“集成原理”会介绍。
资源共享
一旦Mesos和Kubernetes集成完成之后,Kubernetes会作为Mesos的一个Framework运行在Mesos之上。因为一个Mesos可以同时为多个Framework提供资源,当Kubernetes作为Mesos的一个Framework之后,Mesos就可以实现Kubernetes和其它Framework之间的资源共享。
集成原理
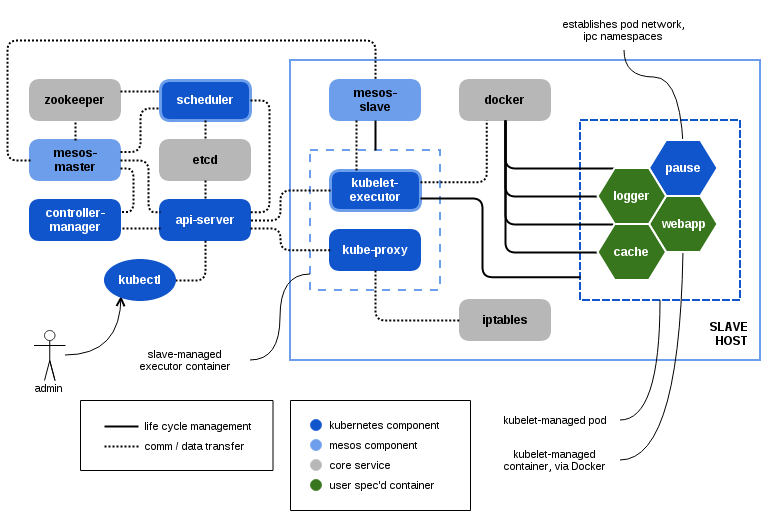
在Kuberntes与Mesos的集成中,Kubernetes的Scheduler会作为Mesos的Framework对Pod与Offer进行匹配;而Kubernetes 的 kubelet 与 kube-proxy则会被新增加的Mesos Executor进行管理来启动相应的Worker并对网络进行配置,从而达到动态扩容的需求。
Kubernetes 与 Mesos集成中包含了多个方面内容;本文的将主要集中介绍资源调度相关部分,后续会有文章介绍其它集成点,如资源执行,环境搭建,测试等等。
Kubernetes Worker节点的创建
k8sm的Kubernetes Worker节点是动态创建的,不需要用户手动创建。创建流程如下:
- 当k8sm的framework注册成功后,马上就会收到Mesos发来的Offer。因为Mesos的Offer都是Coarse-grained Offer,所以当前发来的Offer会包含整个host的全部资源。
- K8sm scheduler收到Offer后,会首先检查当前的Offer是不是合法的,所谓的合法Offer,需要满足两个条件,第一个就当前的这个Offer的资源来自于Kubernetes的某个worker节点,第二个是当前Offer的ExeuctorId必须是没有或者只有一个,并且Offere的ExeuctorId和k8sm scheduler启动时设置的ExeuctorId相同。但是在k8s刚注册的时候,是没有任何worker节点的,这时候k8sm的scheduler做的事情就是Decline这个Offer,即把这个Offer返回给Mesos,但是会把这个Offer对应的host为Kubernetes创建一个worker节点。一个合法的Offer需要满足一下几个条件:
- 当前Offer的资源来自于Kubernetes的某个worker节点。
- 当前Offer的ExeuctorId必须是没有或者只有一个,并且Offer的ExeuctorId和k8sm scheduler启动时设置的ExeuctorId相同。
- 如果当前Offer中只有一个ExecutorId,是否有效合法取决Agent的属性是否有变化:如果属性没有变化,认为Offer是合法的;否则认为是无效的。
- 如此周而复始,一直将Mesos集群中所有的节点加入Kubernetes的worker节点。
- 当有新的Mesos节点加入Mesos集群时,新加入的节点也会给k8sm scheduler发Offer,k8sm scheduler会将新加入的Mesos节点创建为一个Kunernetes的worker节点。
- 所有的Kubenetes worker节点都会存在etcd中。用户可以通过命令“kubectl get nodes”或者直接使用“etcdctl”查看Kubenetes中的所有worker节点。
当Kubernetes Worker节点创建完成后,Mesos再发Offer时,如果发现当前Offer的Host是Kubernetes的一个Worker节点,k8sm scheduler就会把这个Offer作为一个合法的Offer,同时将该Offer缓存起来,默认的缓存时间是5s。
Offer生命周期管理
Framework 实现了 Mesos 的 SchedulerDriver接口;该接口用于Mesos 和 Framework之间的交互。当k8sm scheduler启动后,会创建一个名为 OfferStorage 的 go routine 用于 Offer 的生命周期管理。下面会根据Offer的创建,使用及销毁三个阶段对Offer进行分析。
Offer的创建
如上文描述的,当Framework注册到Mesos上后,Mesos会定期 (–allocation_interval) 向Framework发送Offer。k8sm scheduler 通过以下的原则检测收到的Offer是否合法;如果合法,则放入Offer的缓存中;否则把资源返回给Mesos。
当对Offer进行缓存时,会有两个队列对Offer信息进行存储:delayed 和 Offers。Offers 用于Pod的运行;而当Offer销毁时会使用 delayed 队列;具体的销毁过程会在”Offer的销毁”进行分析。
Offer的使用
在k8sm scheduler启动后,会有一个go routine周期性的检查是不是有新的Pod创建请求。如果有新的Pod创建请求,将这个请求放入k8sm scheduler的任务队列。k8sm scheduler会从这个任务队列取出需要创建的Pod进行调度,调度的主要目的是为当前的Pod找到合适的服务器来运行。
因为Kubernetes是作为Mesos的framework来运行的,所以对Offer的使用主要由两个API来处理:ResourceOffers和LaunchTask。但是对Offer的处理可以主要分为三部分:获取Offer,关联Task和Offer,执行task。每一个Task对应一个Pod。
获取Offer
Offer主要是通过ResourceOffer获取的。这个API是Mesos Framework的API,所有的Frameworkd都需要实现这个API用来接收从Mesos发送来的Offer。前边已经讲了ResourceOffer会触发添加新的Kuernetes worker节点,同时这个Offer会被缓存起来,缓存时间可以通过参数配置,默认是5s。
关联Task和Offer
在k8sm scheduler启动后,会有一个go routine周期性的检查是不是有新的Pod创建请求。如果有新的Pod创建请求,将这个请求放入k8sm scheduler的任务队列。k8sm scheduler会从这个任务队列取出需要创建的Pod进行调度。
在对Pod进行调度的时候,k8sm scheduler回选择将Task和Offer关联。k8sm scheudler现在默认是FCFS算法调度。FCFS对Pod进行调度的时候,主要是为Task挑选合适的Offer,对当前缓存的Offer逐个进行校验,直到为当前的Task选出合适Offer。对Offer的选择主要通过四个方法来进行检验:
- 第一个校验是Node的校验,主要是检查当前Offer的host是不是可以被当前的Pod使用。因为Pod在创建的时候,可以直接在Pod的YAML文件中指定创建的host或者NodeSelector,Node的校验主要是检查当前Offer的host是不是可以为这个Pod所用。如果当前的Host可以为Pod所用,那么当前的Node校验就会把Host作为随后校验的参数;反之则校验下一个Offer。
- 第二个校验是Pod的资源校验,主要是检查当前的Host是不是有足够的资源启动Pod。现在检查的主要是CPU和Memeory。如果资源足够,进行下一个校验。
- 第三个校验主要是端口的校验,主要是检查端口冲突。检查当前Host上的端口是不是可以为Pod所用。
- 第四个校验,也就是最后一个校验,主要是校验Executor。K8sm scheduler主要是使用一个executor管理了所有的task,所以如果Executor校验发现当前Offer中有两个Exeuctor ID,会返回错误,校验下一个Offer;如果发现当前Offer已经包含一个Executor ID了,这时候直接返回,当前Offer可用;如果发现当前Offer中不包含Executor ID,还需要查一下当前的Offer有没有足够的资源启动Executor,如果有足够的资源启动Executor,当前Offer可用。
以上四个校验主要是检查一个Offer是否可用和一个Task绑定。如果检验完成后,Offer可用,k8sm scheduler就会把该Offer和当前Task关联起来。
在Task Launch之前,还会检查下当前的Task是不是关联一个Offer,如果Task没有关联Offer,k8sm scheduler会返回错误,因为Task在运行的时候,必须从某个Offer获取资源才可以运行。
LaunchTask
当Task和Offer关联完成后,k8sm scheduler就开始执行Task了。在执行LaunchTasks之前,需要对Task信息按照Mesos需要的格式进行构建,例如设置Task名字,Task需要的SlaveId,Task需要的资源,Task ID,Task的Executor信息等等。接下来就调用Mesos Framework API LaunchTasks去创建Pod了,具体创建Pod的工作由k8sm的Executor执行。
在Worker节点,Mesos 的 Agent 会负责Executor管理。k8sm的Executor会先创建一个名为MinionServer的对象来负责proxy 和 executor 的管理:proxy通过nsenter, iptables等对网络进行配置;而executor则实现了Mesos Executor接口,用于接收并执行作业,例如在Docker中启动Pod。限于篇幅,网络配置和Pods的执行细节会以后的文章会进行具体的描述。
Offer的销毁
在k8sm scheduler中,以下两种情况会使收到的Offer变不可用状态,从而触发Offer的销毁过程。
- RescindOffer: 在k8sm scheduler使用Offer之前,Mesos在某些情况下会撤回部分Offer,比如设置Quota。当k8sm scheduler收到撤回Offer的请求时,k8sm scheduler 会跟不同情况进行处理:
- 如果是列表中合法的Offer,则通过decline操作把Offer返回给Mesros;如果Mesos对同一个Offer多次撤回,k8sm scheduler会对后继的处理等待2个TTL后再发着decline操作,以确保相应的Worker都已经结束
- 如果Offer已经过期,则不对其进行操作;OfferStorage的go routine会根据 LingerTTL 的设置对Offer进行销毁
- TTL expired: 在Mesos中,如果Mesos不撤回Offer,Framework可以一直持有Offer,直到有相应的作业可以使用这些资源。虽然这减少了作业启动的时候,但是大大降低了资源的使用率。为这了解决这-问题,k8sm引入一两个超时设置: OfferTTL 和 OfferLingerTTL。当Offer超过OfferTTL时,该Offer就认为是无效的Offer;如果OfferLingerTTL为0,则OfferStorage立即通过decline操作将Offer返回给Mesos;如果OfferLingerTTL不为0,则将Offer标识为超时,当OfferLingerTTL再次超时后再将Offer返还给Mesos
当前集成问题及改进方案
资源抢占
虽然Kubernetes运行在Framework之上,可以让Kubernetes和其它Framework共享资源,对系统的资源利用率提升有一定帮助,但是当前的主要问题是Mesos对资源抢占的支持不是太好,现在只支持类似于Resource Scavenge的功能:当资源在被使用的时候,如果使用不充分,Mesos会把使用不充分的资源作为可撤销资源,发给Framwork。Framework可以在这些资源上运行一些优先级不是很高的作业,因为可撤销资源随时可能因为资源的回收而出发杀掉作业的动作。
但是仅仅有这种Resource Scavenge的功能是远远不够的,因为在Mesos集群还可能有大量其它的资源未被使用。例如Reserved(独占)的资源或者Quota(配额)的资源,这些资源目前只能供某个Role/Framework使用,但是如果这些被某个Role/Framework Reserve的资源或者Quota的资源,在当前这个Role/Framework的负载不是很高的情况下,是没办法让其它的Role/Framework去使用的,所以这部分资源就浪费了。
Mesos社区正在通过两个项目来对上述情况做一些改进:Optimistic Offer(MESOS-1607)和Multiple Role Framework (MESOS-1763)。
Optimistic Offer主要是让不同Role/Framework之间的资源能够相互的借入,借出。例如可以将一些使用率不高的Role/Framework的资源借给其它的Role/Framework去使用,如果借出资源的Role/Framework资源请求增大时,可以将借出的资源回收。
Multiple Role Framework主要是让一个Framework可以使用多个Role上提供的资源,如果这个功能实现的话,可以在Kubernetes的Framwork上设置多个Role,通过Optimistic Offer来让不同Role的资源共享。
但是这两个项目在Mesos社区进展很慢,IBM在开源Mesos的基础上,研发了一个Mesos的Allocator插件,通过这个插件,可以实现不同Role/Framework之前资源抢占的功能。
多租户
Kubernetes现在的多租户主要是通过namespace去实现的,不同的namespace可以设置不同的Quota。但是在Mesos中,资源配额是设置在Role中的。如果能将Mesos的Role和Kubernetes的namespace做一些映射的话,同时加上Multiple Role Framework和Optimistic Offer的功能,就可以实现在Kubernetes不同的namespsace之间进行资源共享。
资源调度策略
Mesos做为Kuberentes的资源提供者,为Kuberentes提供了第一级资源调度;Kuberentes作为Mesos的Framework,为用户提供了第二级的资源调度来部署应用。但二者在资源调度上并没有很好的集成在一起,下面的列表描述了调度策略需要改进的问题:
| K8S default conf |
K8S on EGO |
K8S on Mesos |
| PodFitsPorts |
MDS did not support port |
Supported |
| PodFitsResources |
Default behaviour |
Default behaviour |
| NoDiskConflict |
N/A |
N/A |
| MatchNodeSelector |
resreq |
check offered resources |
| HostName |
resreq |
check offered resources |
| ServiceAffinity |
N/A |
N/A |
| LabelsPresence |
resreq + dynamic resources |
N/A |
| LeastRequestedPriority |
N/A |
N/A |
| BalancedResourceAllocation |
Packing |
N/A |
| ServiceSpreadingPriority |
N/A |
N/A |
| EqualPriority |
N/A |
N/A |
| ServiceAntiAffinity |
N/A |
N/A |
Revocable Resources的支持
现在Mesos在allocator这块的改进比较多,主要目的是期望Mesos能够尽量的提升系统的资源利用率。所以Mesos引入了Revocable Resource的概念。所谓的Revocable Resources就是可撤销的资源,这部分资源可以借给某个framework去使用,但是随时可能会被回收,所以Revocalbe Resources主要是执行一些优先级不是很高的作业。有关这个问题的讨论可以参考 https://github.com/mesosphere/kubernetes-mesos/issues/795
k8sm scheduler支持Revocable Resources很简单,主要修改以下的一些逻辑:
- 为k8sm的scheduler启动时加入一个参数指定k8sm framework的capabality可以使用Revocable Resources。
-
Kubernetes Pod在创建的时候,YAML template可以通过annotation指定一些label,这块需要改进能够让用户指定是否想把Pod创建在Revocable Resources之上。
annotation:
k8s.mesosphere.io/revocable: true/false
- 需要改进Pod资源的校验算法,加入对Revocable Resources的校验。
- 在Pod Task launch的时候,为Pod Task的资源设置Revocable属性。
通过以上改动,可以让k8sm scheduler支持使用Revocable Resources。
但是现在的主要问题在于k8sm是一个executor启动所有的Pod/Task,如果executor被杀掉后,所有的Pod/Task都会被杀掉。但是现在Mesos现在对Revocable Resources的回收是直接通过agent去杀executor去实现的,一旦exeuctor被杀死后,所有的Pod/Task也就被杀掉了,所以对于Revocable Resources的使用,Kubernetes可能希望Mesos对Revocable Resources的回收机制做些改进,这些机制目前都在MESOS-1607讨论。
“Unified Container”集成
这个项目(MESOS-2840)的目的是想让Mesos Containizer统一的管理所有的容器技术,包括docker,appc等,但是这个项目对Kubernetes+Mesos的集成影响不是太大,因为Kubernetes的Pod并不是一个单纯的docker container,它可能是一组container向外界提供某个服务,所以目前的Kubernets和Mesos的集成启动Executor还是调用kubelet和kubeproxy来对Pod进行管理。“Unified Container”因为不能对Pod进行管理,所以如果想直接和Kubernetes集成可能不太容易,需要仔细考虑下。
但是“Unified Container”对Swarm的集成影响会比较大,因为Swarm目前主要是依赖Mesos的Docker Containizer调用docker命令创建container,这里边很大的问题是对docker daemon的依赖太大,docker daemon会成为一个单点的不稳定因素,一旦docker daemon挂掉后,这台服务器就不能创建container了,但是“Unified Container”可以保证及时没有docker daemon,也可以创建container,所以可以预见未来Swarm和Mesos的集成很可能迁移到Mesos Containizer。
IBM 测试结果
IBM Container Cloud Team对Kubernetes和Swarm在Mesos上运行做了大量的测试,有关的测试收据可以参考 https://github.com/Open-I-Beam/containers-os/tree/master/kube-mesos。
comments powered by